Üretken Yapay Zeka Sanatı — Generative AI Art
Üretken yapay zeka sanatı muhakkak ki son 5 yılın en ilginç konularından biri olurken, 2023'ün de en ehemmiyetli teknolojisi oldu. Dünya çapında yapay zeka geliştiricileri ile konservatif sanatçıları iki farklı kutba ayırırken, şirketlerin ve devletlerin yeni regülasyonlar konusunda mutabakat sağlamalarını zorunlu kıldı. Son kullanıcılar neyin yapay zeka ile oluşturulduğunu, neyin ise gerçek görüntü olduğunu ayırmakta zorluk çekiyor. Toplumun bir kısmı bu hızla gelişen teknoloji karşısında ürpertiye yakalanırken, kimi ise hemen adapte olup hayatına dahil ediyor. Sosyal medya hesaplarımızda, 16. yüzyılın en ünlü ressamlarından Jacques-Louis David gibi sanatçıların eserlerini andıran selfie’ler oluşturduk, yüzümüzü ünlü kişiliklerin yüzleriyle değiştirdik veya çizgi film karakterlerine büründük. Esasında, bugün ve gelecek dönemler için, gerçek ve sanal dünyada aynı anda bulunan varlıklara dönüştük.

2023 yılı, yapay zekanın geçmiş on yıl içerisinde biriktirdiği kümülatif etkilerin zirveye ulaşarak hayatımızın her alanına nüfuz ettiği bir dönem oldu demek hiç de abartı sayılmaz. Günümüzde, neredeyse her şirket ürünlerine yapay zeka entegrasyonlarını eklemeyi arzuluyor. İnsanlar, akıllı telefonlarına hızla sorular sorup anında cevaplar alabilecekleri uygulamalar yüklüyorlar. Aynı zamanda, büyük teknoloji şirketleri de hedeflerini, yapay zeka odaklı teknolojilere yönlendiriyor. Bu gelişimlerin hem doğal dil, hem de görsel algılama tarafında ilerlemesinin tabii ki bir nedeni var. Bu teknolojik devrim, 2017 yılında Google tarafından yayınlanan “Attention Is All You Need” makalesi ve “Diffusion Mimarisi” olarak adlandırdığımız iki yenilikçi teknolojinin ortaya çıkışıyla mümkün oldu. Bu çalışmalar, yapay zekanın gelişimini hızlandıran ve onu günlük yaşamımızın vazgeçilmez bir parçası haline getiren temel taşlardır.
Üretken sanat (generative art), 1960'lı yıllardan bu yana hayatımızda önemli bir yer tutuyor. Bu dönemde, sanatın ilk temel ve basit örnekleri deneysel ve avant-garde bir pozisyonda yer alıyordu. 1960 ve 1965 yılları arasında, bu eserleri üreten sanatçılar, “üretken sanat” terimini, bilgisayarla oluşturulan geometrik şekiller ve algoritmik olarak üretilen çıktılar bağlamında kullanıyorlardı. Bu alanın öncülerinden biri ve eserleriyle çalışma fırsatı bulduğum Vera Molnar, 1924 doğumlu Macar bir medya sanatçısıydı ve ne yazık ki, 100 yaşına bir hafta kala, 2023 Aralık ayında aramızdan ayrıldı. Vera Molnar, üretken sanatın öncüsü olmasının yanı sıra, bu sanatsal eserlerin üretiminde bilgisayarı kullanan ilk kadınlardan biriydi. Onun çalışmaları, sanat ve teknolojinin kesişimindeki yenilikçi yaklaşımları temsil ediyor ve günümüzdeki dijital sanat anlayışının temellerini atıyor.

Üretken sanat, ya da İngilizce adıyla generative art, var olduğu her dönemde sanat dünyasında karmaşa ve sansasyonel tartışmalara yol açmıştır. Bu sanat dalıyla ilgili akıllara gelen en temel sorulardan biri, bir eser ortaya çıktığında, eserin sahibinin kim olduğuyla ilgilidir: Bu eseri yaratan algoritmayı geliştiren yazılımcı mı, algoritmanın veya yapay zeka modelinin kendisi mi, yoksa eseri hayal eden ve kendi hikayesini, tarzını yansıtan sanatçı mı? Bu konu her zaman tartışmalı olmuştur. Geliştirilen yazılım veya yapay zeka modeli, bir bakıma sistemsel özerkliğe benzetilebilir. Bir yanda, fırça ve tuvali kullanarak ve sinirsel motor sistemlerine dayanarak eser yaratan insan sanatçı bulunurken, diğer yanda algoritmaları kuran, bunları şekillendiren ve bu yolla sanat üreten yazılımcılar bulunmaktadır. Bu, sanatın tanımı ve sınırları üzerine derinlemesine düşünmeye davet eden bir ikilemdir.
Bu hassas konuları geride bıraktığımızda, bugün geldiğimiz noktada, Turing testlerinden başarıyla geçebilen, bazen bizi ürküten, bazen de heyecanlandıran bir yapay zeka teknolojisine sahibiz. Bu eserleri oluşturmamızda büyük bir rol oynayan, arkasındaki büyüleyici matematiğe birazdan değineceğim. Elbette, bu gelişmelerin gerçekleşmesi, donanım ve yazılım teknolojilerinin bu kadar ilerlemesine bağlı. Ancak, bu sanat eserlerini üretmek için oldukça yüksek bilgisayar gücü gerekiyor. Eğer yüzlerce ekran kartı, güçlü işlemciler, iyi bir matematik ve istatistik bilgisine sahipseniz ve aynı zamanda sanatsal ve estetik bir ruha sahipseniz, üretken yapay zeka sanatı geliştiricisi olabilirsiniz. Bu, hem teknolojik hem de sanatsal yeteneklerin birleştiği, son derece özgün ve yenilikçi bir alandır.
Üretken Yapay Zeka Sanatı
“Üretici yapay zeka” terimi, yazı, görsel, ses veya farklı formatlarda medya üretimi üzerine geliştirilen yapay zeka modellerini tanımlamak için kullanılır. Bu alana, günümüzde yaygın olarak kullanılan ChatGPT gibi yazı tabanlı soru-cevap yapay zeka teknolojileri de dahildir. Müzik, şiir veya edebiyat gibi alanlar sanatın önemli parçaları olmakla birlikte, teknolojinin gelişim süreci nedeniyle üretici yapay zeka sanatı, genellikle yanlış bir algı ile, özellikle görsel alanla ilişkilendirilir. Bu yazıda da, üretici yapay zeka sanatını esas olarak görsel bağlamda ele alacağım.

Üretken sanatın ilk dönemlerinde, modeller genellikle daha basit matematiksel programlama teknikleri kullanılarak geliştiriliyordu. Bunlara ek olarak, robotik kollar, rastgele sayı üreteçleri ve çeşitli algoritmalar daha sık kullanılıyordu. Zamanla, görüntü işleme tekniklerinin gelişmesi ve bu tekniklerin derin öğrenme ile birleştirilmesi fikri, yapay zekanın sanat üretiminde daha etkin bir rol almasını sağladı. Bu gelişmeler, üretici yapay zeka sanatının bugünkü sofistike ve görsel olarak zengin formuna evrilmesine ön ayak oldu.
AICAN
Bu alandaki öncü örneklerden biri, Rutgers Üniversitesi’nde Dr. Ahmed Elgammal ve ekibi tarafından geliştirilen AICAN (Yapay Zeka Yaratıcı Rekabet Ağı) sistemidir. AICAN, Barok, Rokoko ve Soyut Dışavurumculuk gibi çeşitli sanat tarzları üzerine eğitilmiş bir üretken yapay zeka modelidir. Bu sistemin en dikkat çekici özelliklerinden biri, daha önce hiç görülmemiş yeni sanat tarzlarını keşfetme ve yaratma kabiliyetidir. Temel olarak, görsel üretmek için eğitilmiş bir yapay sinir ağının değişkenlerini manipüle ederek yeni görseller üretebilmek üzerine çalışır. Aşağıdaki görselde, AICAN sistemi tarafından yaratılan üretken bir yapay zeka sanat eserini görebilirsiniz.

AICAN, yapay zekanın sanat dünyasındaki rolünü yeniden tanımlıyor ve geleneksel sanat anlayışlarını dönüştürerek sanatın geleceği üzerinde önemli bir etki yaratıyor. Bu sistem, teknoloji ve sanatın bir arada nasıl yeni estetik anlayışlar ve yaratıcı ifadeler üretebileceğinin somut bir örneğini sunmaktadır.
CLIP
OpenAI tarafından geliştirilen CLIP, yapay zeka mimarisi alanında önemli bir yenilik olarak karşımıza çıkıyor. Şu anda kullanılan birçok sanatsal model bu mimariyi temel alıyor. CLIP’in özelliği, görselleri ve bu görsellere ait tanımlamaları eşleştiren bir zeka modeline dayanmasıdır. Yani, yazı ve görsel içerikleri anlamsal bir bağlamda, ortak bir uzayda eşleştiriyor. Matematiksel bir uzayda tüm görselleri ve bunlara karşılık gelen tanımları bir matriste tanımlama yeteneğimiz bu model sayesinde mümkün hale gelmiştir. En etkileyici özelliği ise, metinden görsel üretime ve görselden metin oluşturmaya olanak sağlamasıdır. Bu, metin ve görsel içerikler arasında zengin ve karmaşık bir etkileşim kurabilmemizi sağlayan bir teknolojidir, böylece yapay zekanın yaratıcı potansiyelini yeni boyutlara taşımaktadır.

GANs
GAN’ler, yani Üretken Çekişmeli Ağlar, temelde iki sinir ağından oluşan bir makine öğrenimi algoritması türüdür: bir üreteç ve bir ayırt edici. Üreteç ağı, eğitim veri setine benzer yeni veri örnekleri, örneğin görüntüler veya sesler üretirken; ayırt edici ağ, üretilen örnekler ile gerçek olanları ayırt etmeyi öğrenir. Rekabetçi bir süreç aracılığıyla, iki ağ birbirleriyle yarışır, ta ki üreteç, ayırt ediciyi kandırabilecek gerçekçi örnekler üretene kadar.
Üretken Çekişmeli Ağlar (GAN’ler) bağlamında, “örtük uzay” (latent space), görüntüler veya diğer verileri üretmek için kullanılan giriş değişkenleridir. Bir GAN’da, üreteç ağı bir dizi gizli değişkeni girdi olarak alır ve bu değişkenlere dayanarak bir görüntü veya diğer veriler üretir. Ayırt edici ağ ise, üretilen çıktıyı değerlendirir ve üretecin çıktısını nasıl iyileştirebileceği konusunda geri bildirim sağlar.

Bir GAN’ı eğitmenin amacı, örtük uzay ile veri alanı arasındaki eşleşmeyi öğrenmektir, böylece üreteç ağı, belirli bir gizli değişken kümesine dayalı olarak gerçekçi ve yüksek kaliteli çıktılar üretebilir.
Ve sonrasında, bahsedilen gizli alanı kontrol etmek için kullanılabilecek yeni bir teknik geliştirildi. Bu teknik, GAN modelimizi yönetmek için daha önce bahsettiğim CLIP modelini kullanma fikriydi. Görüntüyle çıktıyı eşleştiren bir yapay zeka modelimiz zaten mevcuttu, artık görüntülerle eğittiğimiz yapay zeka modelimizi isteklerle (prompt) kontrol etmek son derece etkileyici bir gelişme oldu. Bu, kararlı difüzyon gibi bugün kullandığımız tüm tekniklerin temel yapı taşlarından biridir.
Diffusion
Ve artık, üretken yapay zeka sanatının altın çağını başlatan devrimsel bir mimariye ulaştığımızı söyleyebiliriz. Muhtemelen son zamanlarda Twitter’da veya diğer sosyal medya platformlarında, Midjourney veya Stable Diffusion gibi araçlarla, fikirlerinizi veya hayallerinizi basit bir cümleyle (istem veya prompt) hayata geçiren görsellerle karşılaşmışsınızdır.
Aslında bu tür çalışmalar, “Latent Diffusion” ya da Türkçesiyle “Örtük Yayılım” adı verilen bir yapay zeka mimarisinin bir ürünüdür. Örtük yayılım modelleri, eğitim görüntülerinin istatistiksel dağılımını öğrenerek ve bu dağılımı yeni, benzersiz görüntüler oluşturmak için kullanarak çalışır. Bu yapay zeka modelleri, milyarlarca fotoğraf ve bunlara eşlik eden açıklamaları öğrenerek yeni görseller yaratmanıza olanak tanır. Model eğitildikten sonra, öğrenilen dağılımdan örnekleme yoluyla yeni, benzersiz görseller oluşturmak mümkündür.
Bu örnekleme süreci, modelin örtük uzayında, bir görüntüyü tanımlayan benzersiz özellikler setine karşılık gelen rastgele bir noktanın seçilmesini içerir. Model, örtük uzaydaki farklı noktalara dayanarak görseller üretir ve böylece, stil ve içerik açısından orijinal eğitim görüntülerine benzeyen, farklı görüntüler yaratır. Bu karmaşık süreci, sadece hayal gücünüzü yazıya dökerek (CLIP modelinde kullandığımız gibi) kontrol edebilirsiniz, bu da sanatsal ifade ve teknolojinin kesişim noktasında yeni ufuklar açar.
Teorik
Stable Diffusion modeli, görüntü oluşturma sürecinde bir dizi karmaşık bileşeni entegre eder. Bunlar arasında VAE (varyasyonel otoenkoder), Tokenizer ve Metin Kodlayıcı, UNet ve Zamanlayıcı (Scheduler) bulunmaktadır.
Diffüzyon sürecinin temel amacı, fotoğraflara yavaş yavaş gürültü eklemek ve her adımda modelin bu gürültüyü nasıl kaldıracağını öğrenmesini sağlamaktır. Modelin çıkarım aşamasında, verdiğimiz rastgele gürültü girdisini kaldırarak görsel oluşturmasını bekliyoruz. Gürültü ekleme süreci lineer olmayan bir şekilde gerçekleşir.

Gürültü Zamanlaması (Noise Schedule), farklı zaman adımlarında ne kadar gürültü ekleneceğini belirler. Örneğin, ‘DDPM’ (“Denoising Diffusion Probabilistic Models”) makalesinde tanımlanan bir yaklaşım, gürültü ekleme sürecini açıklamaktadır.

Diffusion modelinde gürültü ekleme süreci lineer olarak gerçekleşmez. Lineer bir gürültü ekleme süreci, fotoğrafın hızlı bir şekilde tamamen gürültülü bir forma dönüşmesine neden olur. Bu nedenle, daha kontrollü bir gürültü ekleme süreci için kosinüs yaklaşımını kullanılır.
Zamanlamacının iki temel görevi vardır:
- Zamanlayıcı ile birlikte görüntüye iteratif olarak gürültü eklemek.
- Fotoğraftaki gürültü kaldırılırken bir sonraki zaman adımında görüntünün nasıl güncelleneceğini belirlemek.
Diffüzyon modellerinde, VAE kullanılır. Bu, görüntünün gizli bir uzayda daha küçük bir temsilini sağlar. Örneğin, 512x512x3 boyutundaki bir görsel, 64x64x4 boyutuna indirgenir.
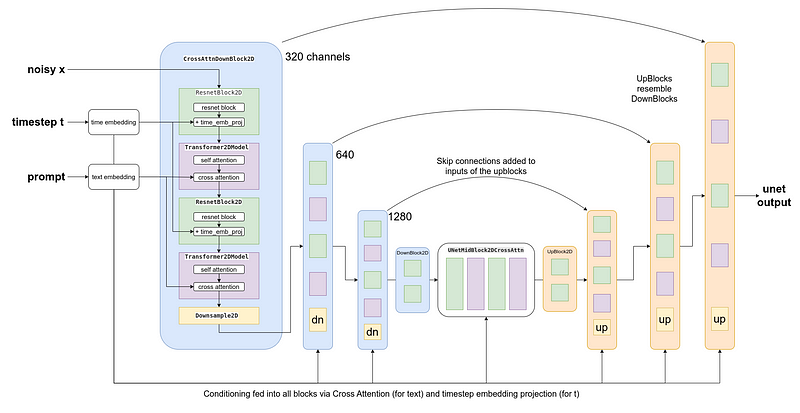
Metin Koşullandırması (Text Conditioning), diffüzyon modeli eğitilirken, görselin oluşumunda etkili olacak şekilde metin verilerinin de bilgi olarak eklenmesidir. Burada amaç, gürültülü bir görsel verildiğinde, modelin metne uygun bir şekilde gürültüyü çözmesi ve görselin buna göre oluşmasıdır.
Çıkarım anında, başlangıçta saf gürültü ve oluşturmak istediğimiz görsel ile uyumlu bir metin verilir ve modelin rastgele bir girdiyi metne göre oluşturması istenir. Metin koşullandırmasını oluşturmak için yine CLIP modeli kullanılır.
Çapraz Dikkat(Cross Attention), modelin son çıktısı başlangıçta kullanılan gürültü girdisine oldukça bağlı olduğundan, bu durumu dengelemek için Classifier Free Guidance (Sınıflandırıcı Serbest Yönlendirme — CFG) adı verilen bir yöntem kullanılır. Kısaca, model eğitim sırasında metin bilgisi olmadan eğitilir, çıkarım anında ise sıfır koşullandırma ve metin koşullandırması ile iki tahmin yapılır. Bu iki tahmin arasındaki fark, CFG olarak adlandırılır.
Ayrıca Super-resolution, Inpainting ve Depth to Image gibi farklı koşullandırmalar da vardır. Super-resolution, fotoğrafın yüksek çözünürlüklü hali ve düşük çözünürlüklü hali üzerinde eğitim gerçekleştirilirken; depth to image, görüntünün kendisi ve derinlik haritası ile koşullandırılarak eğitilir.
Kapanış
Bu yazımı kapatırken, üretken sanatın ne tamamen geleneksel anlamda bir sanat olduğunu ne de sadece bir programlama disiplini olduğunu belirtmem gerekiyor. Aslında bu, hem ikisi hem de hiçbiri olarak tanımlanabilir. Yazılım, tanım itibarıyla insan ve bilgisayar arasındaki bir iletişim arayüzüdür. Sanat ise, duygularla derinden bağlantılı bir alan olup, bu kadar duygusal bir konuyu tek bir tanımla sınırlamak hata olurdu. Üretken sanat, bu iki grift ve birbirinden farklı dünyayı bir araya getirir. Üretken yapay zeka ise buna ek olarak derin bir matematik ekler, insanı taklit eder ve gerçeklik algımızı sarsar. Bu konuda kesin bir hükme varmak için henüz çok erken. Üretken sanat, sanat ve teknolojinin kesiştiği, sürekli evrilen ve sınırları zorlayan bir alandır.